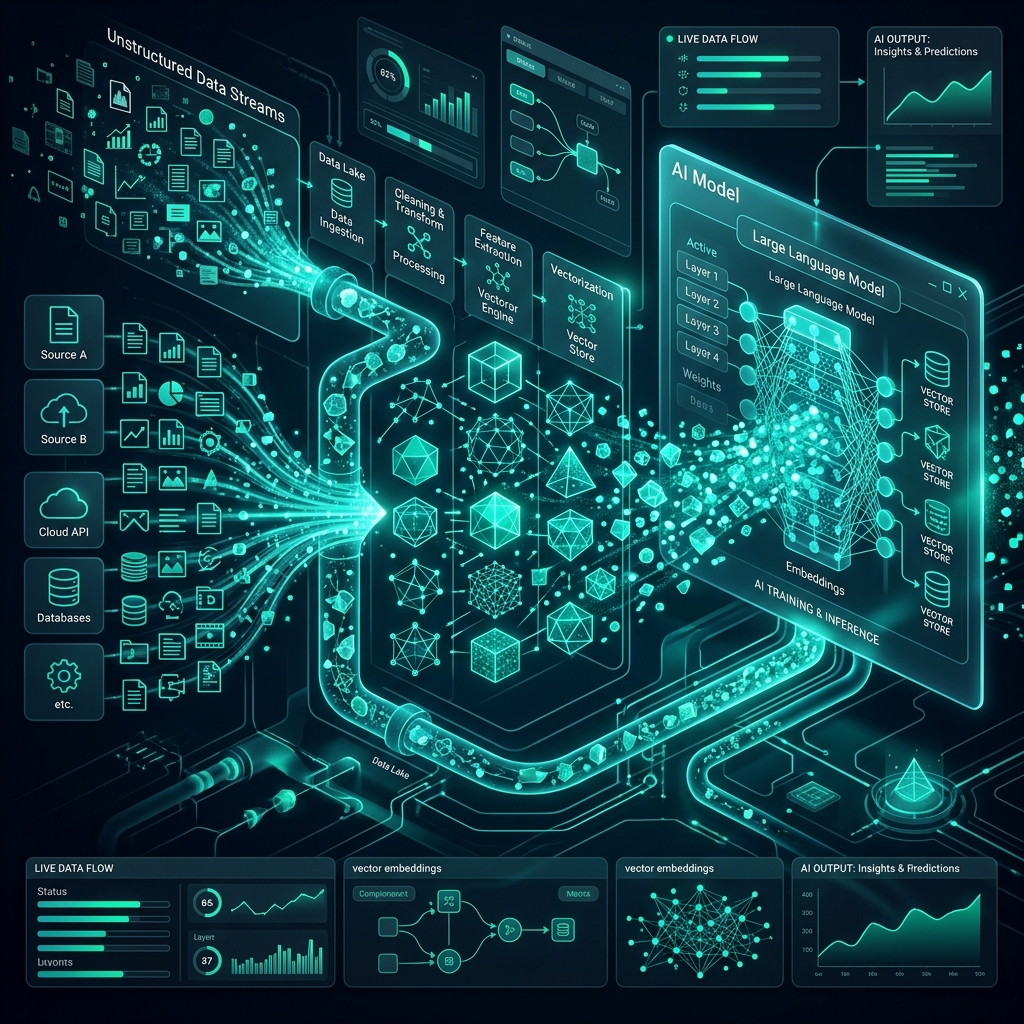
Se a Inteligência Artificial é o motor, os dados são o combustível. Mas os modelos de IA Generativa não “bebem” dados tabulares do PostgreSQL ou arquivos CSV crus facilmente. Eles exigem um novo formato: Contexto Vetorizado e Semântico.
O Fim do ETL como Conhecíamos
A tradicional extração e carga de dados em Data Warehouses (ETL) foi otimizada para Business Intelligence (BI). Para a IA, um painel no QuickSight não basta. O modelo precisa entender o significado daquele dado no momento em que está conversando com o usuário.
O Surgimento do ETC (Extract, Transform and Context)
Engenheiros de Dados em 2026 estão construindo pipelines totalmente novos focados em alimentar o “Contexto” de LLMs:
- Chunking Inteligente: Dividir longos manuais da empresa não por parágrafos fixos, mas por blocos lógicos usando processamento de linguagem natural (NLP).
- Metadata Enrichment: Adicionar tags de metadados a cada bloco de texto. Isso garante que o RAG possa filtrar por “Ano=2026” ou “Departamento=RH” antes mesmo de rodar a busca vetorial pesada.
- Data Quality como Prevenção de Alucinação: Se entra lixo, sai lixo (com muita confiança). O pipeline moderno exige validação de integridade nos dados desestruturados antes de transformá-los em embeddings.
Nesta era, o Engenheiro de Dados não apenas move bytes; ele estrutura o “conhecimento do mundo” para as máquinas lerem.